
Srikanta Mishra and Jared Schuetter, Battelle Memorial Institute; Akhil Datta-Gupta, SPE, Texas A&M University; and Grant Bromhal, National Energy Technology Laboratory, US Department of Energy
Algorithms are taking over the world, or so we are led to believe, given their growing pervasiveness in multiple fields of human endeavor such as consumer marketing, finance, design and manufacturing, health care, politics, sports, etc. The focus of this article is to examine where things stand in regard to the application of these techniques for managing subsurface energy resources in domains such as conventional and unconventional oil and gas, geologic carbon sequestration, and geothermal energy.
It is useful to start with some definitions to establish a common vocabulary.
- Data analytics (DA)—Sophisticated data collection and analysis to understand and model hidden patterns and relationships in complex, multivariate data sets
- Machine learning (ML)—Building a model between predictors and response, where an algorithm (often a black box) is used to infer the underlying input/output relationship from the data
- Artificial intelligence (AI)—Applying a predictive model with new data to make decisions without human intervention (and with the possibility of feedback for model updating)
Thus, DA can be thought of as a broad framework that helps determine what happened (descriptive analytics), why it happened (diagnostic analytics), what will happen (predictive analytics), or how can we make something happen (prescriptive analytics) (Sankaran et al. 2019). Although DA is built upon a foundation of classical statistics and optimization, it has increasingly come to rely upon ML, especially for predictive and prescriptive analytics (Donoho 2017). While the terms DA, ML, and AI are often used interchangeably, it is important to recognize that ML is basically a subset of DA and a core enabling element of the broader application for the decision-making construct that is AI.
In recent years, there has been a proliferation in studies using ML for predictive analytics in the context of subsurface energy resources. Consider how the number of papers on ML in the OnePetro database has been increasing exponentially since 1990 (Fig. 1). These trends are also reflected in the number of technical sessions devoted to ML/AI topics in conferences organized by SPE, AAPG, and SEG among others; as wells as books targeted to practitioners in these professions (Holdaway 2014; Mishra and Datta-Gupta 2017; Mohaghegh 2017; Misra et al. 2019).

Given these high levels of activity, our goal is to provide some observations and recommendations on the practice of data-driven model building using ML techniques. The observations are motivated by our belief that some geoscientists and petroleum engineers may be jumping the gun by applying these techniques in an ad hoc manner without any foundational understanding, whereas others may be holding off on using these methods because they do not have any formal ML training and could benefit from some concrete advice on the subject. The recommendations are conditioned by our experience in applying both conventional statistical modeling and data analytics approaches to practical problems. To that end, we ask and (try to) answer the following questions:
- Why ML models and when?
- One model or many?
- Which predictors matter?
- Can data-driven models become physics-informed?
- What are some challenges going forward?
Why ML Models and When?
Historically, subsurface science and engineering analyses have relied on mechanistic (physics-based) models, which include a causal understanding of input/output relationships. Unsurprisingly, experienced professionals are wary of purely data-driven black-box ML models that appear to be devoid of any such understanding. Nevertheless, the use of ML models is easy to justify if the relevant physics-based model is computation intensive or immature or a suitable mechanistic modeling paradigm does not exist. Furthermore, Holm (2019) posits that, even though humans cannot assess how a black-box model arrives at a particular answer, such models can be useful in science and engineering in certain cases. The three cases that she identifies, and some corresponding oil and gas examples, follow.
- When the cost of a wrong answer is low relative to the value of a correct answer (e.g., using an ML-based proxy model to carry out initial explorations in the parameter space during history matching, with further refinements in the vicinity of the optimal solution applied using a full-physics model)
- When they produce the best results (e.g., using a large number of pregenerated images to seed a pattern-recognition algorithm for matching the observed pressure derivative signature to an underlying conceptual model during well-test analysis)
- As tools to inspire and guide human inquiry (e.g., using operational and historical data for electrical submersible pumps in unconventional wells to understand the factors and conditions responsible for equipment failure or suboptimal performance and perform preventative maintenance as needed)
It should be noted that data-driven modeling does not preclude the use of conventional statistical models such as linear/linearized regression, principal component analysis for dimension reduction, or cluster analysis to identify natural groupings within the data (in addition to, or as an alternative to, black-box models). This sets up the data-modeling culture vs. algorithm-modeling culture debate as first noted by Breiman (2001). In our view, the two approaches can and should coexist, with ML methods being preferred if they are clearly superior in terms of predictive accuracy, albeit often at the cost of interpretability. If both approaches provide comparable results at comparable speeds, then conventional statistical models should be chosen because of their transparency.
One Model or Many?
Although the concept of a single correct model has been conventional wisdom for quite some time, the practice of geostatistics has influenced the growing acceptance that multiple plausible geologic models (and their equivalent dynamic reservoir models) can exist (Coburn et al. 2007). This issue of nonuniqueness can be extended readily to other application domains such as drilling, production, and predictive maintenance. The idea of an ensemble of acceptable models simply recognizes that every model—through its assumptions, architecture, and parameterization—has a unique way of characterizing the relationships between the predictors and the responses. Furthermore, multiple such models can provide very similar fits to training or test data, although their performance with respect to future predictions or identification of variable importance can be quite different.
Much like a “wisdom of crowds” sentiment for decision-making at the societal level, ensemble modeling approaches combine predictions from different models with the goal of improving predictions beyond what a single model can provide. They have also routinely appeared as top solutions to the well-known Kaggle data analysis competitions. Approaches for model aggregation may include a simple unweighted average of all model predictions or a weighted average based on model goodness of fit (e.g., root-mean-squared error or a similar error metric). Alternatively, multiple model predictions can be combined using a process called stacking, where a set of base models are used to predict the response of interest using the original inputs, and then their predictions are used as predictors in a final ML-based model, as shown in the work flow of Fig. 2 (Schuetter et al. 2019).

Given that there is no a priori way to choose the best ML algorithm for a problem at hand, at least in our experience, we recommend starting with a simple linear regression or classification model (ideally, no ML model should underperform this base model). This would be supplemented by one or more tree-based models [e.g., random forest (RF) or gradient boosting machine (GBM)] and one or more nontree-based models [e.g., support vector machine (SVM) or artificial neural network (ANN)]. Because of their architecture, tree-based models can be quite robust, sidestepping many issues that tend to plague conventional statistical models (e.g., monotone transformation of predictors, collinearity, sensitivity to outliers, and normality assumptions). They also tend to produce good performance without excessive tuning, so they are generally easy to train and use. Models such as SVM and ANN require more effort to implement—in the former case, because of the need to be more careful with predictor representation and outliers, and, in the latter case, because of the large number of tuning parameters and resources required; however, they traditionally also have shown better performance.
The suite of acceptable models, based on a goodness-of-fit threshold, would then be combined using the model aggregation concepts described earlier. The benefits would be robust predictions as well as ranking of variable interactions that integrate multiple perspectives.
Which Predictors Matter?
For black-box models, we strongly believe that it is not just sufficient to obtain the model prediction (i.e., what will happen) but also necessary to understand how the predictors are affecting the response (i.e., why will it happen). At some point, every model should require human review to understand what it does because (a) all models are wrong (thanks, George Box), (b) all models are based on assumptions, and (c) humans have a tendency to be overconfident in models and use them even when those assumptions are violated. To that end, answering the question “Which predictors matter?” can help provide some inkling into the inner workings of the black-box model and, thus, addresses the issue of model interpretability. In fact, one of the biggest pushbacks against the widespread adoption of ML models is the perception of lack of transparency in the black-box modeling paradigm (Holm 2019). Therefore, it is important to ensure that a robust approach toward determining (and communicating) variable importance is an integral element of the work flow for data-driven modeling using ML methods.
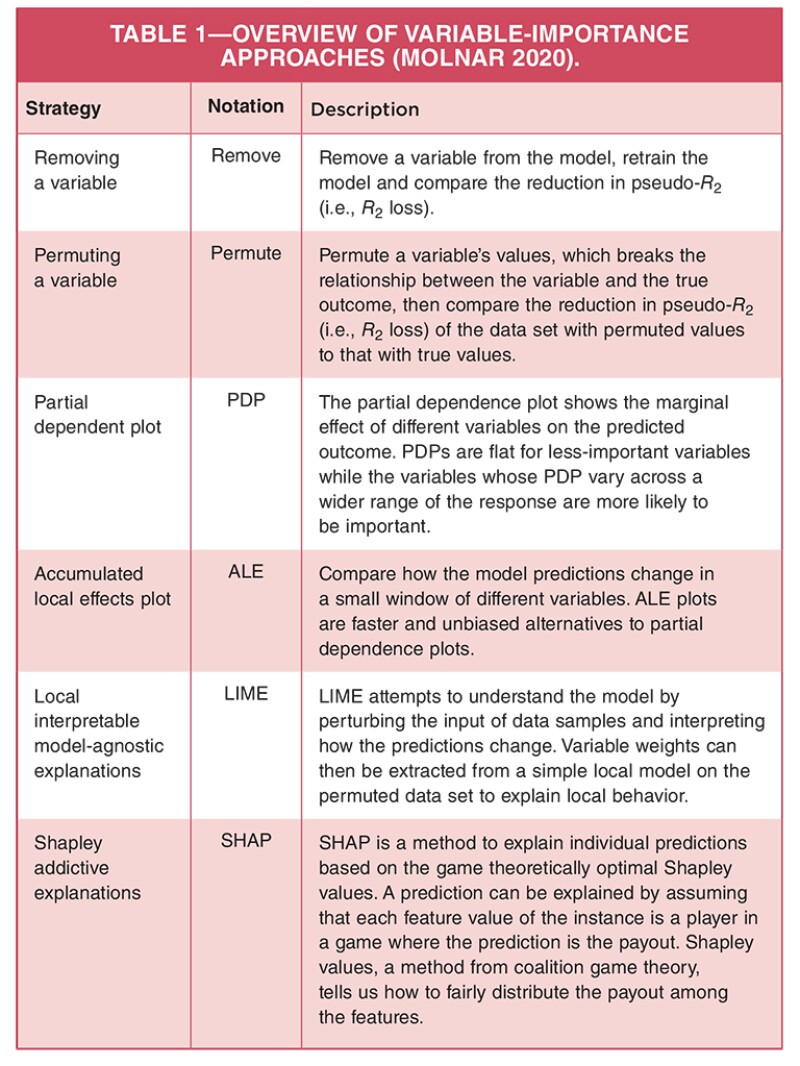
A review of the subsurface ML modeling literature suggests that ranking of input variables (predictors) with respect to their effect on the output variable of interest (response) seems to be carried out sporadically and mostly when the ML algorithm used in the study happens to include a built-in importance metric (as in the case of RF, GBM, or certain ANN implementations). In our experience, it is more useful to consider a model-agnostic variable-importance strategy, which also lends itself to the ensemble modeling construct. This can help create a meta-ranking of importance across multiple plausible models (much like using a panel of judges in a figure skating competition).
As Schuetter et al. (2018) have shown, the importance rankings may fluctuate from model to model, but, collectively, they provide a more robust perspective on the relative importance of predictors aggregated across multiple models. Some of those model-independent
importance-ranking approaches, as explained in detail in Molnar (2020), are summarized in Table 1. We have found the Permute approach to be the most robust and easy to implement and explain without incurring any significant additional computational burden beyond the original model fitting process.
Can Data-Driven Models Become Physics-Informed?
Standard data-driven ML algorithms are trained solely based on data. To ensure good predictive power, the training typically requires large amounts of data that may not be readily available, particularly during early stages of field development. Even if adequate data are available, there often is difficulty in interpreting the results or the results may be physically unrealistic. To address these challenges, a new class of physics-informed ML is being actively investigated (Raissi et al. 2019). The loss function in a data-driven ML (such as ANN) typically consists of only the data misfit term. In contrast, in the
physics-informed neural network (PINN) modeling approaches, the models are trained to minimize the data misfit while accounting for the underlying physics, typically described by governing partial differential equations. This ensures physically consistent predictions and lower data requirements because the solution space is constrained by physical laws. For subsurface flow and transport modeling using PINN, the residual of the governing mass balance equations is typically used as the additional term in the loss function.
For illustrative purposes, Fig. 3 shows 3D pressure maps in an unconventional reservoir generated using the PINN approach and comparison with a standard neural network (NN) approach. To train the PINN, the loss function here is set as L=Ld+Lr, where Ld is the data misfit in terms of initial pressure, boundary pressure, and gas production rate and Lr is the residual with respect to the governing mass-balance equation that is specified using a computationally efficient Eikonal form of the original equations (Zhang et al. 2016). Almost identical results are obtained using the PINN and standard NN in terms of matching the gas production rate. However, the pressure maps generated using the PINN show close agreement with 3D numerical simulation results, whereas the standard NN shows pressure depletion over a much larger region. Furthermore, the predictions using the PINN are two orders of magnitude faster than the 3D numerical simulator for this example.

What Are Some Key Challenges Going Forward?
Next, we address some of the lingering questions and comments that commonly have been raised during the first author’s SPE Distinguished Lecture question and answer sessions, in industry/research oriented technical forums related to ML, and from conversations with decision-makers and stakeholders.
“Our ML models are not very good.” Consumer marketing and social-media entities (e.g., Google, Facebook, Netflix) are forced to use ML/AI models to predict human behavior because there is no mechanistic modeling alternative. There is a general (but mistaken) perception in our industry that these models must be highly accurate (because they are used so often), whereas subsurface ML models can show higher errors depending on the problem being solved, the size of training data set, and the inclusion of relevant causal variables. We need to manage the (misplaced) expectation about subsurface ML models having to provide near-perfect fits to data and focus more on how the data-driven model can serve as a complement to physics-based models and add value for decision-making. Also, the application of ML models in predictive mode for a different set of geological conditions (spatially) or extending into the future where a different flow regime might be valid (temporally) should be treated with caution because data-driven models have limited ability to project the unseen. In other words, past may not always be prologue for such models.
“If I don’t understand the model, how can I believe it?” This common human reaction to anything that lies beyond one’s sphere of knowledge can be countered by a multipronged approach: (a) articulating the extent to which the predictors span the space of the most relevant causal variables for the problem of interest, (b) demonstrating the robustness of the model with both training and (cross) validation data sets, (c) explaining how the predictors affect the response to provide insights into the inner workings of the model by using variable importance and conditional sensitivity analysis (Mishra and Datta-Gupta 2017), and (d) supplementing this understanding of input/output relationships through creative visualizations.
“We are still looking for the ‘Aha!’ moment. Another common refrain against ML models is that they fail to produce some profound insights on system behavior that were not known before. There are times when a data-driven model will produce insights that are novel, whereas, in other situations, it will merely substantiate conventional subject-matter expertise on key factors affecting the system response. The value of the ML model in either case lies in providing a quantitative data-driven framework for describing the input/output relationships, which should prove useful to the domain expert whenever a physics-model takes too long to run, requires more data than is readily available, or is at an immature or evolving state.
“My staff need to learn data science, but how?” There appears to be a grassroots trend where petroleum engineers and geoscientists are trying to reinvent themselves by informally picking up some knowledge of machine learning and statistics from open sources such as YouTube videos, code and scripts from GitHub, and online courses. Following Donoho (2017), we believe that becoming a citizen data scientist (i.e., one who learns from data) requires more—that is, formally supplementing one’s domain expertise with knowledge of conventional data analysis (from statistics), programming in Python/R (from computer science), and machine learning (from both statistics and computer science). Organizations, therefore, should promote a training regime for their subsurface engineers and scientists that provides such competencies.
In the context of technology advancement and workforce upskilling, it is worth pointing out a recently launched initiative by the US Department of Energy known as Science-Informed Machine Learning for Accelerating Real-Time Decisions in Subsurface Applications (SMART) (https://edx.netl.doe.gov/smart/) . This initiative is funded by DOE’s Carbon Storage and Upstream Oil and Gas Program and has three main focus areas:
- Real-time visualization—to enable dramatic improvements in the visualization of key subsurface features and flows by exploiting machine learning to substantially increase speed and enhance detail
- Real-time forecasting—to transform reservoir management by rapid analysis of real-time data and rapid forward prediction under uncertainty to inform operational decisions
- Virtual learning—to develop a computer-based experiential learning environment to improve field development and monitoring strategies
The SMART team is engaging with university, national laboratory, and industry partners and is building off of ongoing and historical data collected from DOE-supported field laboratories and regional partnerships and initiatives since the early 2000s. A key area of experimentation within SMART is the use of deep-learning techniques (e.g., convolution and graph neural networks, auto encoder/decoder, long short-term memory) for building 3D spatiotemporal data-driven models on the basis of field observations or synthetic data.
Epilogue
The buzz surrounding DA and AI/ML from multiple business, health, social, and applied science domains has found its way into several oil and gas (and related subsurface science and engineering) applications. Within our area of work, there is significant ongoing activity related to technology adaptation and development, as well as both informal and formal upskilling of geoenergy professionals to create citizen data scientists. The current status of this field, however, can best be classified as somewhat immature; it reminds us of the situation with geostatistics in the early 1990s, when the potential of the technology was beginning to be realized by the industry but was not yet fully adopted for mainstream applications.
To that end, we have highlighted several issues that should be properly addressed for making data-driven models more robust (i.e., accurate, efficient, understandable, and useful) while promoting foundational understanding of ML-related technologies among petroleum engineers and geoscientists. We believe that an appropriate mindset should be not to treat these data-driven modeling problems as merely curve-fitting exercises using very flexible and powerful algorithms easily abused for overfitting but to try to extract insights based on data that can be translated into actionable information for making better decisions. As the poet T.S. Eliot has said: “Where is the wisdom we have lost in knowledge? Where is the knowledge we have lost in information?” By extension, where is the information that is hiding in our data? May these thoughts help guide our journey toward better ML-based data-driven models for subsurface energy resource applications.
References
Breiman, L. 2001. Statistical Modeling: The Two Cultures. Statistical Science 16: 199–231.
Coburn, T.C., Yarus, T.M., and Chambers, R.L. 2007. Stochastic Modeling and Geostatistics: Principles, Methods, and Case Studies, Volume II. AAPG. https://doi.org/10.1306/CA51063.
Donoho, D. 2017. 50 Years of Data Science. Journal of Computational and Graphical Statistics 26 (4): 745–766.
Hastie, T., Tibshirani, R., and J.H. Friedman, 2008. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Springer, New York, NY.
Holdaway, K. 2014. Harness Oil and Gas Big Data With Analytics: Optimize Exploration and Production With Data-Driven Models. New York: John Wiley & Sons.
Holm, E. 2019. In Defense of the Black Box. Science 364: 26–27.
Mishra, S., and Datta-Gupta, A. 2017. Applied Statistical Modeling and Data Analytics for the Petroleum Geosciences. New York: Elsevier.
Misra, S., Li, H., and He, J. 2019. Machine Learning in Subsurface Characterization. Houston: Gulf Professional Publishing.
Mohaghegh, S. 2017. Data-Driven Reservoir Modeling. Richardson, Texas: Society of Petroleum Engineers.
Molnar, C. 2020. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable. https://christophm.github.io/interpretable-ml-book (accessed 8 February 2021).
Raissi, M., Perdikaris, P., and Karniadakis, G.E. 2019. Physics-Informed Neural Networks: A Deep Learning Framework for Solving Forward and Inverse Problems involving nonlinear partial differential equations. Journal of Computational Physics 378: 686-707.
Sankaran, S., Matringe, S., Sidahmed, M., et al. 2020. Data Analytics in Reservoir Engineering. Richardson, Texas: Society of Petroleum Engineers.
Schuetter, J., Mishra, S., Zhong, M.; et al. 2018. A Data Analytics Tutorial: Building Predictive Models for Oil Production in an Unconventional Shale Reservoir, SPE J. 23 (4): 1,075–1,089. SPE-189969-PA. https://doi.org/10.2118/189969-PA.
Schuetter, J., Mishra, S., Lin, L., et al. 2019. Ensemble Learning: A Robust Paradigm for Data-Driven Modeling in Unconventional Reservoirs. Unconventional Resources Technology Conference, Denver, 22–24 July. https://doi.org/10.15530/urtec-2019-929.
Zhang, Y., Bansal, N., Fujita, Y., et al. 2016. From Streamlines to Fast Marching: Rapid Simulation and Performance Assessment of Shale Gas Reservoirs Using Diffusive Time of Flight as a Spatial Coordinate, SPE J. 21 (5): 1,883–1,898. SPE-168997-PA. https://doi.org/10.2118/168997-PA.

Srikanta Mishra, SPE, is technical director for geo-energy modeling and analytics at Battelle Memorial Institute. His expertise is in integrating computational modeling and machine-learning-assisted data-driven activities for subsurface energy projects. Mishra was an SPE Distinguished Lecturer in 2018–19, speaking on big-data analytics. He is the author of approximately 200 refereed publications, conference papers, and technical reports and the book Applied Statistical Modeling and Data Analytics for the Petroleum Geosciences. Mishra holds a PhD degree in petroleum engineering from Stanford University. He may be contacted at [email protected].

Jared Schuetter is senior data scientist at Battelle. He has spent more than 10 years working on problems that require a blend of statistical and machine-learning/artificial-intelligence approaches. Schuetter holds a PhD degree in statistics. He may be contacted at [email protected].

Akhil Datta-Gupta, SPE, is regents professor, university distinguished professor, and L.F. Peterson Endowed Chair professor in the Harold Vance Department of Petroleum Engineering at Texas A&M University. His research interests include high-resolution flow simulation, petroleum reservoir management/optimization, large-scale parameter estimation by use of inverse methods, and uncertainty quantification. Datta-Gupta holds a PhD degree in petroleum engineering from The University of Texas at Austin. He is an SPE Honorary Member and received SPE’s Lester C. Uren Award in 2003 and John Franklin Carll Award in 2009 and was elected to the US National Academy of Engineering in 2012. Datta-Gupta may be contacted at [email protected].

Grant S. Bromhal is senior fellow for geological and environmental systems at the National Energy Technology Laboratory and technical director of the Science-Informed Machine Learning for Accelerating Real-Time Decisions in Subsurface Applications Initiative. In 2018–19, he served as acting director of research for the US Department of Energy’s Office of Oil and Gas. Bromhal holds a PhD degree in civil and environmental engineering from Carnegie Mellon and bachelor’s degree in civil engineering and math from West Virginia University. He may be contacted at [email protected].
