Rapid Forecast Calibration Using Nonlinear Simulation Regression With Localization
You have access to this full article to experience the outstanding content available to SPE members and JPT subscribers.
To ensure continued access to JPT’s content, please Sign In, JOIN SPE, or Subscribe to JPT
The industry increasingly relies on forecasts from reservoir models for reservoir management and decision making. However, because forecasts from reservoir models carry large uncertainties, calibrating them as soon as data come in is crucial. Traditional probabilistic history matching remains time-consuming because it needs to calibrate the models before using them to update probability distributions (S-curves) of quantities of interest (QOIs). This paper presents a direct forecast method called simulation regression with localization (SRL), which is able to calibrate the forecast with observed data without calibrating the model.
Introduction
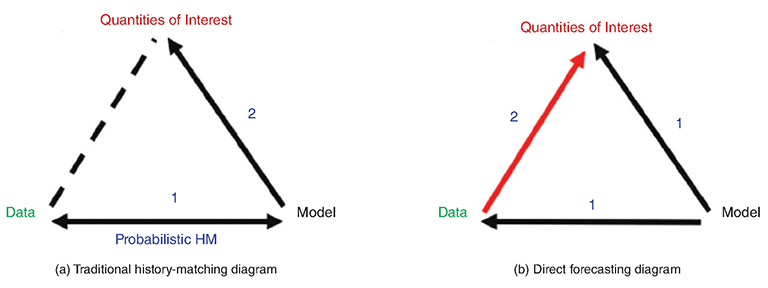
Production forecasts from reservoir-simulation models can be affected by the various uncertainties present in the subsurface, such as those in the geological characterization and rock and fluid properties. Calibrating uncertain QOIs, such as production-forecast or key subsurface parameters, to observation data is a crucial element in the context of closed-loop reservoir management. Traditionally, this task is accomplished by a two-step approach, as depicted in Fig. 1a.

First, a probabilistic history-matching process needs to be carried out to condition the simulation models to the data. Probabilistic history matching generates an ensemble of reservoir models that characterize the posterior uncertainty given the measurement data (e.g., historical well-test and production data), as opposed to deterministic history matching, in which only one model that best matches the measurement data is generated.
In the second step, reservoir simulations, subject to a given reservoir operation plan, are performed on the generated posterior samples, or models, to estimate the posterior distribution of the QOIs. There is rich literature on various probabilistic history-matching methods, and the complete paper cites and assesses several examples. However, the authors state that, although much progress has been made in probabilistic history matching, the resulting procedures still are generally time-consuming for realistic systems, and may not provide accurate sampling of posterior distribution when strong nonlinearity and non-Gaussianity exist.
Proposed Work Flow
The complete paper explores an alternative forecasting framework, as shown in Fig. 1b. The authors propose using SRL for direct forecasting to derive the posterior distributions for QOIs given the measurement data. As with other direct forecasting methods, the first step of SRL is to perform an ensemble of simulation runs according to the previous distributions of the uncertainties and construct a training data set for the QOIs and measurement data. Then, in SRL, a regression model is built on this training data set to estimate the mean value of the posterior distribution. Depending on the case at hand, this regression model can be as simple as a linear regression model, or as complex as a deep-learning model.
The authors found that the quadratic partial least square (QPLS) regression model offers flexibility to handle a wide range of problems. However, the posterior variances of the QOIs are estimated by a localization process wherein the mismatch of the regression model for samples closed to observed data is used to estimate the posterior variance. Finally, the entire posterior distribution (in terms of the cumulative distribution function; i.e., the S-curve) can be estimated by scaling the prior S-curve with the updated mean and variance.
Simulation regression has been used to predict the expected values of the development project given geophysical data for value of information calculation. However, the authors write that this is the first time it has been used to derive the entire posterior S-curve (including the posterior variance estimation and the S-curve scaling) for the QOIs. The complete paper investigates SRL with both linear regression and QPLS regression models, and the results are benchmarked with those from rejection sampling (which serves as a reference) and from a recently proposed method called ensemble variance analysis (EVA). The sensitivities of the method’s performance to the size of the training data set and to data error are also investigated.
The complete paper is organized as follows. The authors present the problem formulation and the concepts and notations that will be used throughout the paper. Then, the methodology of SRL is presented in detail, followed by an application of the method on a synthetic problem with the Brugge reservoir model. The results are benchmarked with those from rejection sampling and EVA. After that, a sensitivity study is presented to demonstrate the effect of training data set size and the data error. The paper concludes with a discussion of the benefits and limitations of the proposed method and potential future work.
In the proposed work flow, a set of samples is drawn from the prior distribution of the uncertainty parameter space, and simulations are performed on these samples. The simulated data and values of the objective functions are then assembled into a database, and a functional relationship between the perturbed simulated data (simulated data plus error) and the objective function is established through nonlinear regression methods such as nonlinear partial least square (NPLS) with automatic parameter selection. The prediction from this regression model provides estimates for the mean of the posterior distribution. The posterior variance is estimated by a localization technique. The proposed methodology is applied to a data-assimilation problem on a field-scale reservoir model. The posterior distributions from the authors’ approach are validated with reference solution from rejection sampling and then compared with EVA. EVA, which is based on a linear-Gaussian assumption, is shown to be equivalent to simulation regression with a linear regression function. It is also shown that the use of NPLS regression and localization in the proposed workflow eliminates the numerical artifact from the linear-Gaussian assumption and provides substantially better prediction results when strong nonlinearity exists. Systematic sensitivity studies have shown that the improvement is most dramatic when the number of training samples is large and the data errors are small. The proposed nonlinear simulation-regression procedure naturally incorporates data error and enables the estimation of the posterior variance of objective quantities through an intuitive localization approach. The method provides an efficient alternative to a traditional two-step approach (probabilistic history matching and then forecast) and offers improved performance over other existing methods. In addition, the sensitivity studies related to the number of training runs and measurement errors provide insights into the necessity of introducing nonlinear treatments in estimating the posterior distribution of various objective quantities. A summary of the findings is as follows:
- EVA is equivalent to simulation regression with a linear regression model and without localization.
- SRL with a nonlinear regression model (i.e., QPLS) outperforms EVA in cases in which the relationship between data and QOIs is nonlinear.
- Localization improves prediction accuracy for posterior variance estimate.
- When data noise is significant, simulation-regression procedures with linear and nonlinear regression models provide similar prediction accuracy.
Discussion
In SRL, a regression model built on an ensemble of simulation results of data and QOI is used to generate an estimate of the posterior mean of the QOI. The posterior variance is estimated by calculating the prediction error of the regression model in the vicinity of the observed data. Finally, the entire posterior S-curve can be constructed by scaling the prior S-curve to the updated mean and variance.
Through theoretical derivation, it is proven that the recently proposed EVA is a special case of SRL in which the linear regression is used and no localization is applied. Through a synthetic but realistic example, it is demonstrated that, by using a nonlinear regression model such as quadratic partial least square regression, and localization, SRL can provide much-improved posterior mean and variance estimate vs. EVA, given the same simulation data set. The improvement is most notable for cases in which the joint distribution of data and QOIs are non-Gaussian and heteroskedastic.
Through sensitivity analysis, such performance is revealed to be consistent for a wide range of ensemble sizes used. The improvement is most notable for cases in which the data error is small. In this work, the QOIs are treated individually and only their S-curves are investigated (histogram/marginal distribution).
S-curves alone do not reflect how QOIs correlate with each other after the data assimilation. Future work should be focused on extending this approach to predict the joint distribution of multiple QOIs. In addition, in this work, the number of samples used for localization (Nl) is determined heuristically as a percentage of the total number of samples. As mentioned previously, the choice of Nl can significantly affect the performance of localization and is worthy of further investigation. Finally, in this work, the authors benchmarked the proposed method with rejection sampling and compared its performance with EVA. With the recent advances in direct forecasting, benchmarking the proposed method with other recently proposed techniques, such as data space inversion, would be of interest.

{kind=link}