
When you need an answer, and you need it fast, wouldn’t it be nice to ask everyone in the world who could help find an answer?
While yes, this would be great, it would also likely take an obscene amount of time, and be pretty expensive. Instead, it’s a better idea to gather your data by asking a select number of people that have the information you need.
This method is known as data sampling.
What is data sampling?
Data sampling is a common statistics technique that’s used to analyze patterns and trends in a subset of data that’s representative of a larger data set being examined. Sampling is used to determine how much data to collect and how often it should be collected.
There’s a lot to consider with data sampling, as this form of statistical analysis can go very wrong if you don’t do it right, and it can require a good amount of research that needs to be conducted before sampling can begin.
For specific information about data sampling, jump ahead to:
Probability sampling methods
Non-probability sampling methods
Understanding data sampling errors
Advantages of data sampling
Challenges of data sampling
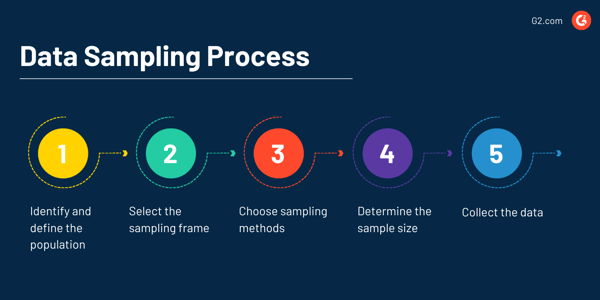
Process of data sampling
The overall process of data sampling is a statistical analysis method that helps to draw conclusions about populations from samples.
The first step when data sampling is to identify and define the population you’re looking to analyze. This can be done by carrying out surveys, opinion polls, various observations, focus groups, questionnaires, or interviews.
This step can also be referred to as data collection. Parameters need to be set — whether it’s decided to only survey women between the ages of 18-35 or men who graduated from college in 2010 in the state of Vermont.
Next, select the sampling frame, which is the list of items or people forming a population in which the sample is taken. An example of a sampling frame could be the names of people who live in a specific town for a survey being conducted regarding family size in that town.
Then a sampling method will be chosen. These methods are broken down into two main categories: probability sampling and non-probability sampling. Each category, as well as the methods in them, are detailed below.
The fourth step is to determine the sample size to analyze. In data sampling, the sample size is the exact number of samples that will be measured for an observation to be made.
Let’s say your population will be men who graduated from college in 2010 in the state of Vermont, and that number is 40,000, then the sample size will be 40,000. The larger the sample size, the more accurate the conclusion will be.
Finally, it’s time to collect data from the sample. You’ll then either make a decision, conclusion, or actionable plan based on what the data presents.
Data sampling methods
Step three in the data sampling process hinges on the method of data sampling you choose to use. There are various methods to select from within two categories: probability sampling and non-probability sampling.
Probability sampling
In the category of probability sampling, every aspect of the population has an equal chance of being selected to be studied and analyzed. These methods typically provide the best chance of creating a sample that’s as representative as possible.
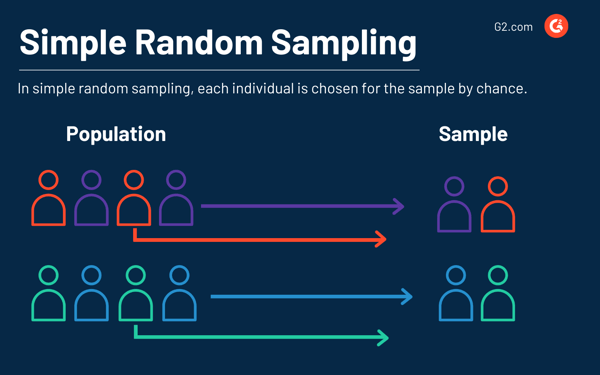
Simple random sampling
The simple random method of data sampling is, like the name suggests, random. Each individual is chosen by chance, and each member of the population or group has an equal chance of being selected.
Those going this route may even use software to choose at random since it’s used when there isn’t any kind of prior information about the target population.
As an example, say your business has a marketing team of 50 people, and you need 10 of them on a new project that’s about to launch. Each team member has an equal chance of being selected with a probability of 5%.
An advantage of using simple random would be that this method is the most direct way to perform probability sampling. On the other hand, those using simple random sampling may find that those selected don’t have the characteristics in which they’re looking to study.
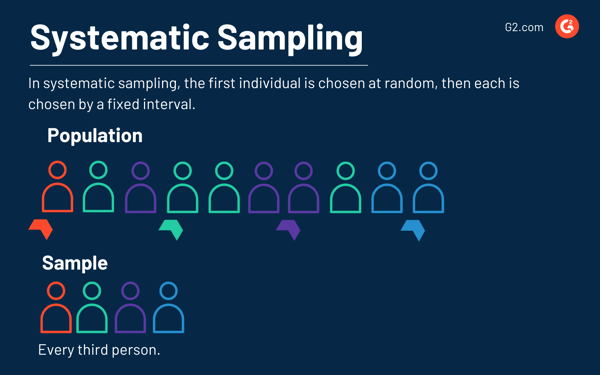
Systematic sampling
Systematic sampling is a little more complicated. In this method, the first individual is selected randomly, while others are selected using a “fixed sampling interval”. Therefore, a sample is created by setting an interval that derives data from the larger population.
An example of systematic data sampling would be choosing the first individual at random, then choosing every third person for the sample.
Some clear advantages to using systematic sampling are that it’s easy to execute and understand, you have full control of the process, and there’s a low-risk factor to contamination of data.
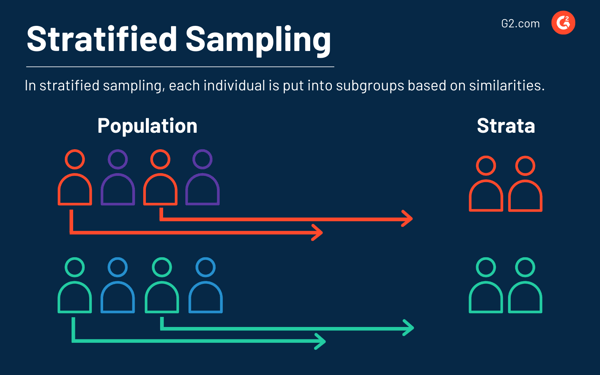
Stratified sampling
Stratified sampling is a method where elements of the population are divided into small subgroups, called stratas, based on their similarities or a common factor. Samples are then randomly collected from each subgroup.
This method requires prior information about the population, to determine the common factor, before creating the strata.These similarities can be anything from hair color, the year they graduated from college, the type of dog they have, food allergies, etc.
An advantage of stratified sampling is that this method can provide greater precision than other methods. Because of this, you can choose to test a smaller sample.
Cluster sampling
The method of clustering divides the entire population, or large data set, into clusters, or sections, based on a defining factor. Then the clusters are randomly selected to be put in the sample and then analyzed.
Let’s say each cluster is based on which Chicago neighborhood the individuals live in. These individuals are clustered by Wrigleyville, Lincoln Park, River North, Wicker Park, Lakeview, and Fulton Market. Then, the sample of individuals is randomly chosen to be represented by those living in Wicker Park.
This method of sampling is also a quick and less expensive method and allows for a large sample of data to be studied. Cluster sampling can also allow for a large number of data points from a complete demographic or community since it’s specifically designed for large populations.

Multistage sampling
Multistage sampling is a more complicated form of cluster sampling. Essentially, this method works by dividing the larger population into many clusters. The second-stage clusters are then broken down further based on a secondary factor. Then, those clusters are sampled and analyzed.
The “staging” in multistage sampling continues as multiple subsets continue to be identified, clustered, and analyzed.
Non-probability sampling
The data sampling methods in the non-probability category have elements that don’t have an equal chance of being selected to be included in the sample, meaning they don’t rely on randomization. These techniques rely on the ability of the data scientist, data analyst, or whoever is doing the selecting, to choose the elements for a sample.
Because of this, these methods run the risk of ending up with a non-representational sample, which is a group that doesn’t truly represent the sample. This could result in a generalized conclusion.
Convenience sampling
In convenience sampling, sometimes called accidental or availability sampling, the data is collected from an easily accessible and available group. Essentially, individuals are selected based on their availability and willingness to be a part of the sample.
This method of data sampling is typically used when the availability of a sample is rare and expensive. It’s also prone to bias, since the sample may not always represent the specific characteristics needed to be studied.
Let’s go back to the example we used for simple random sampling. You still need 10 members of your marketing team to assist with a specific project. Instead of selecting team members at random, you select the 10 who are most willing to help.
This method has the advantage of being easy to carry out at a relatively low cost in a timely manner. It also allows for gathering useful data and information from a less formal list, like the methods used in probability sampling. Convenience sampling is the preferred method for pilot studies and hypothesis generation.
Quota sampling
When the quota method is used in data sampling, items are chosen based on predetermined characteristics. The researcher doing the data sampling ensures equal representation within the sample for all subgroups within the data set or population.
Quota sampling depends on the preset standard. For example, the population being analyzed is 75% women and 25% men. However, since the sample should reflect the same percentage of women and men, only 25% of the women will be chosen to be in the sample, to match the 25% of men.
Quota sampling is ideal for those who need to consider population proportions, while also remaining cost-effective. Quota sampling is also easy to administer once characters are determined.
Judgment sampling
Judgment sampling, which is also known as selective sampling, is based on the assessment of experts in the field when choosing who to ask to be included in the sample.
In this case, let’s say you are selecting from a group of women aged 30-35, and the experts decide that only the women who have a college degree will be best suited to be included in the sample. This would be judgment sampling.
Judgment sampling takes less time than other methods, and since there’s a smaller data set, researchers should conduct interviews and other hands-on collection techniques to ensure the right type of focus group. Since judgment sampling means researchers can go directly to the target population, there’s an increased relevance of the entirety of the sample.
Snowball sampling
The snowball sampling, sometimes also called referral sampling or chain referral sampling, is used when the population is completely rare and unknown.
This is typically done by selecting one, or a small group, of individuals based on the specific criteria. Then, the person(s) selected are then used to find more individuals to be analyzed.
Consider a situation or topic that is highly sensitive, like contracting a contagious disease. These individuals may not openly discuss their situation or participate in surveys to share information regarding the disease.
Since not all people with this disease will respond to questions asked, the researcher can choose to contact people they know, or those that have the disease may get in touch with others they know who also have it, to collect the information needed.
This method is called snowballing because, since existing people are asked to nominate people to be in the sample, the same increases in size like a rolling snowball.
Snowball sampling means that a researcher can reach a specific population that would be difficult to sample using other methods, while still keeping costs down. It also needs little planning and a fewer workforce on-hand, due to the smaller sample size.
Data resampling
Once you have a data sample, this can be used to estimate the population. However, since this only gives you a single estimate, there isn’t any variability or certainty in the estimate. Because of this, some researchers estimate the population multiple times from one data sample, which is called data resampling.
Each new estimate is referred to as a subsample since it’s from the original data sample. Each sample that estimates the population from resampling is its own statistical tool to quantify the accuracy of the sample.
Understanding data sampling errors
When data sampling occurs, it requires those involved to make statistical conclusions about the population from a series of observations.
Because these observations often come from estimations or generalizations, errors are bound to occur. The two main types of errors that occur when performing data sampling are:
- Selection bias: The bias that’s introduced by the selection of individuals to be part of the sample that isn’t random. Therefore, the sample cannot be representative of the population that is looking to be analyzed.
- Sampling error: The statistical error that occurs when the researcher doesn’t select a sample that represents the entire population of data. When this happens, the results found in the sample don’t represent the results that would have been obtained from the entire population.
The only way to 100% eliminate the chance of a sampling error is to test 100% of the population. Of course, this is usually impossible. However, the larger the sample size in your data, the less extreme the margin of error will be.

Advantages of data sampling
There’s a reason why data sampling is so popular, as there are many advantages.
For starters, it’s useful when the data set that needs to be examined is too large to be analyzed as a whole. An example of this is big data analytics, which looks at raw, massive sets of data in an attempt to uncover trends.
In these cases, identifying and analyzing a representative sample of data is more efficient, as well as cost-effective, than trying to survey the entirety of data or population. In addition to being low-cost, analyzing a sample of data takes less time than trying to analyze the entire population of data.
It’s also a great option if resources are limited at your business. Studying the entire population of data would require not only time and money but also varying equipment. If supplies are limited, data sampling is an appropriate strategy to consider.
Challenges of data sampling
There are some challenges or drawbacks of data sampling that could come up during the process. An important factor to consider when data sampling is the size of the required sample and the possibility of experiencing a sampling error, in addition to sample bias.
When delving into data sampling, a small sample could reveal the most important information that’s needed from a data set. However, in other cases, using a large sample can increase the likelihood of accurately representing the dataset as a whole — even if the increased size of the sample may interfere with manipulation and interpretation of that data.
Because of this, some may run into difficulties in selecting a truly representative sample for the more reliable and accurate results.
There’s no such thing as a free sample
At least, not when it comes to your data. It’s going to take time and effort, no matter which method you choose.
Narrow down the size of the population you want to analyze, roll up your sleeves, and get started. The solid numbers your business needs to make data-driven decisions are just a sample away!
For some help with data sampling, make the most out of statistical analysis software, which can not only assist in determining a sample size and analyzing the data but also in coming up with various conclusions and hypotheses once sampling is complete.

{kind=link}