


One of the most popular algorithms used in statistical analysis, Logistic Regression is a great tool for predictive analysis and has its applications firm rooted in Machine Learning. The algorithm is a classifier, which in Machine Learning or Data Science context refers to the ability to predict categorical values as opposed to Regression Algorithms which predicts continuous values. Logistic regression sometimes called the Logit Model predicts based on probability using the logistic regression equation.
In this article, we will learn to implement the Logistic regression in R programming language. Readers are expected to have some basic understanding of the language.
Understanding the Logistic Regressor
Before we dive into the implementation part let us understand a bit more about the popular Logistic Regression.

It is easier to confuse Logistic Regression as a Regression algorithm due to the “Regression” attached to its name, but as mentioned earlier, it is a pure classification model that can predict dependent variables that falls into specific categories.
To put it in a much simpler way, Logistic regression works when your dependent variable(s) is/are categories like yes or no, male or female or variables that fall into multiple categories like States, Currencies, Brands or Countries etc.

The Logistic Regression Equation:
The logistic regression equation is derived from the Linear regression and Sigmoid function.
The Linear equation gives us :
![]()
Sigmoid function after substituting for y from the above equation :
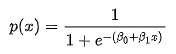
The resulting solution is called the Logistic Regression Equation
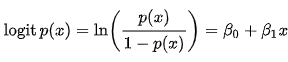
Now let us try to understand the equation with one of the simplest illustrations available on the internet. The following graph depicts the plot between the time a student spends studying versus whether he/she passes or fails the test.
Clearly what we are trying to predict falls in a binary category since there are only two possible outcomes either the student fails(0) or passes(1).

The logistic regression equation represented by the blue line in the graph determines the category by pointing towards the probability. Consider from the given graph, if a student studies for only 2 hours the probability for passing the test is only 0.25 or 25 %, represented by the red lines. If the student studies for 5 hours the probability of passing the test is above 0.9 or 90%. Thus probability determines whether the student passes or fails. For predictive analysis, we fix a critical value or threshold probability score, say for example 50% or 0.5. If the probability falls above 0.5 the student passes otherwise the student fails.
Implementing Logistic Regression in R
To understand Logistic Regression in R we will use the dataset from Machninehack’s Predict The Data Scientists Salary In India Hackathon. To get the dataset head to Machnehack, sign up and download the datasets from the Attachment Section.
Having trouble finding the data set? Click here to go through the tutorial to help yourself.
Lets Code!
For the time being, we will just use a subset of the dataset provided at Machinehack. We will only consider two features from the dataset, the locations and salary. Apparently, the problem is about predicting the salary range of Data Scientists across India. We will use Logistic Regression to see if the factor location alone will impact the salary of a Data Scientist.
#Importing the dataset
data = read.csv('Final_Train_Dataset.csv')
dataset = data[7:8] # preferred subset
Let’s have a look at the dataset:
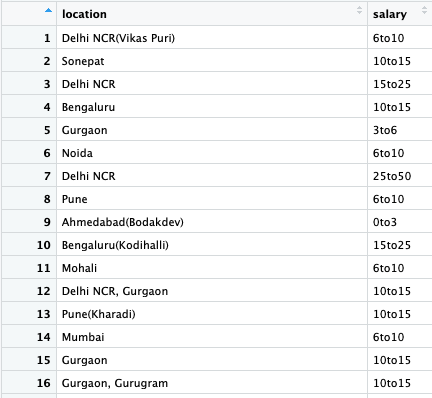
#Label Encoding
library(CatEncoders)
categ_enc = LabelEncoder.fit(dataset$location)
dataset$location = transform(categ_enc,dataset$location)
res = LabelEncoder.fit(dataset$salary)
dataset$salary = transform(res,dataset$salary)
After encoding we will have something like this :
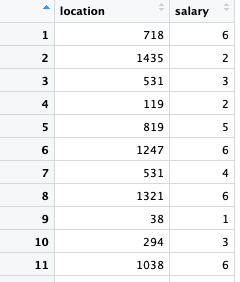
# Splitting the dataset into the Training set and Test set
library(caTools)
set.seed(123)
split = sample.split(dataset$salary, SplitRatio = 0.80)
trainingset = subset(dataset, split == TRUE)
testset = subset(dataset, split == FALSE)
Building the Logistic Regression Model
# building and trainig the model
library(nnet)
library(magrittr)
model <- nnet::multinom(salary ~., data = trainingset)
# Summarize the model
summary(model)
Output:

# Make predictions
predicted.classes <- model %>% predict(testset)
head(predicted.classes)
Output :

# Model accuracy
mean(predicted.classes == testset$salary)
Output:
![]()
We got a pretty low score of 23% accuracy in predictions. This suggests that location alone can not be used to determine the salary of data scientists across the country.

{kind=link}